Service hotline
+86 0755-83044319

release time:2022-03-17Author source:SlkorBrowse:13336
RISC-V has been one of the hottest topics in computing because this instruction set architecture (ISA) allows for extensive customization and is easy to understand, in addition to the whole open source, license-free benefit. There's even a project to design a general-purpose GPU based on the RISC-V ISA, and now we're witnessing the porting of Nvidia's CUDA software library to the Vortex RISC-V GPGPU platform.
Nvidia's CUDA (Computing Unified Device Architecture) represents a unique computing platform and application programming interface (API) that runs on Nvidia's line of graphics cards. When an application is written for CUDA support, as soon as the system discovers a CUDA-based GPU, it gets a lot of GPU acceleration of the code.
Today, researchers investigated a way to enable CUDA software toolkit support on a RISC-V GPGPU project called Vortex. The Vortex RISC-V GPGPU is designed to provide a system-wide RISC-V GPU based on the RV32IMF ISA. This means that 32-bit cores can scale from 1-core to 32-core GPU designs. It supports the OpenCL 1.2 graphics API, and today it also supports some CUDA operations.
The researchers explain: "...In this project, we propose and build a pipeline to support end-to-end CUDA migration: the pipeline accepts CUDA source code as input and executes them on the extended RISC-V GPU architecture. Our The pipeline consists of several steps: translate CUDA source code to NVVM IR, convert NVVM IR to SPIR-V IR, forward SPIR-V IR to POCL to get RISC-V binary, and finally execute on extended RISC-V GPU Binary file architecture."
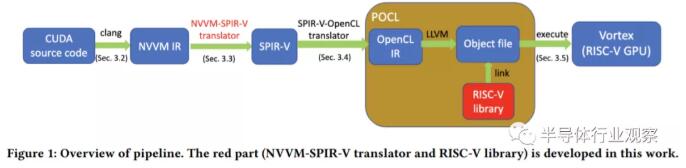
The process is visualized in the image above, showing all the steps to make it work. In simple terms, CUDA source code is represented in an intermediate representation (IR) format called NVVM IR, based on the open source LLVM IR. It was later converted to Standard Portable Intermediate Representation (SPIR-V) IR, which was then forwarded into a portable open-source implementation of the OpenCL standard, called POCL. Since Vortex supports OpenCL, it provides supported code and can execute it without problems.
For more details on this complex process, click below to read the original article. Importantly, you must thank these researchers for their efforts to make CUDA run on RISC-V GPGPUs. While this is only a small step for now, it could be the beginning of an era where RISC-V is used to accelerate computing applications, much like Nvidia's GPU lineup today.
Extended reading: Can RISC-V change the GPU?
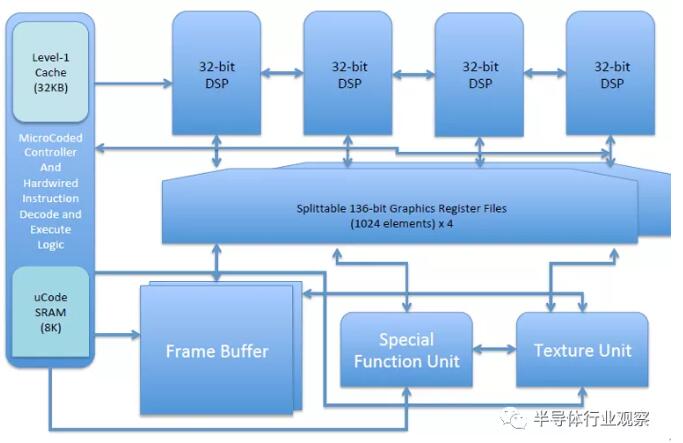
Instruction/Data SRAM cache (32 kB)
Microcode SRAM (8 kB)
Dual function instruction decoder (hardwired for RV32V and X; microcoded instruction decoder for custom ISA)
Quad-vector ALU (32-bit/ALU-fixed/float)
136-bit register file (1k elements)
special function unit
texture unit
Configurable local framebuffer
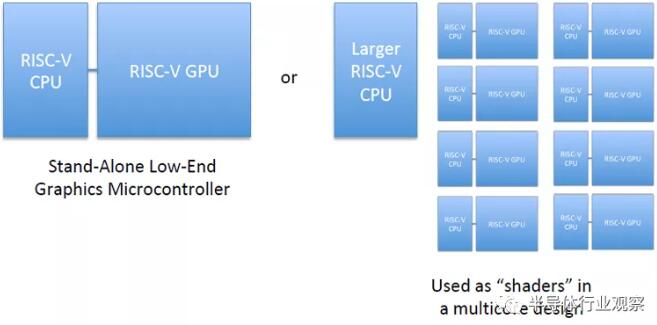
The RV64X specification is still in early development and subject to change. A discussion forum is being established. The immediate goal is to build an example implementation using the instruction set simulator. This will open usingSource IP and FPGA implementations of custom IP designed as open source projects.
Disclaimer: This article is reproduced from "Semiconductor Industry Observation". This article only represents the author's personal opinion, not the opinion of Sac Micro and the industry, only for reprinting and sharing, support To protect intellectual property rights, please indicate the original source and author for reprinting. If there is any infringement, please contact us to delete it.






Site Map | 萨科微 | 金航标 | Slkor | Kinghelm
RU | FR | DE | IT | ES | PT | JA | KO | AR | TR | TH | MS | VI | MG | FA | ZH-TW | HR | BG | SD| GD | SN | SM | PS | LB | KY | KU | HAW | CO | AM | UZ | TG | SU | ST | ML | KK | NY | ZU | YO | TE | TA | SO| PA| NE | MN | MI | LA | LO | KM | KN
| JW | IG | HMN | HA | EO | CEB | BS | BN | UR | HT | KA | EU | AZ | HY | YI |MK | IS | BE | CY | GA | SW | SV | AF | FA | TR | TH | MT | HU | GL | ET | NL | DA | CS | FI | EL | HI | NO | PL | RO | CA | TL | IW | LV | ID | LT | SR | SQ | SL | UK
Copyright ©2015-2025 Shenzhen Slkor Micro Semicon Co., Ltd
